|
Israel D. Gebru I'm a Research Scientist at Meta Codec Avatars Lab in Pittsburgh, where I develop novel machine learning models for speech and audio to power the next generation of conversational agents and immersive telepresence experiences in VR/AR. My research sits at the intersection of signal processing, machine learning, and multimodal understanding, aiming to make virtual communication as natural and immersive as face-to-face interaction. I have made significant contributions to speech and spatial audio modeling, including work on streaming neural audio codecs, binaural speech synthesis, neural rendering models for room acoustics and 6DoF ambient sound, as well as techniques for converting ambisonic recordings into spatialized binaural audio. I was among the early researchers to develop neural network–based approaches to binaural audio generation. Before joining Meta, I earned a PhD in Mathematics and Computer Science from INRIA and Université Grenoble-Alpes in France, under the supervision of Dr. Radu Patrice Horaud . During this time, I was also a visiting researcher at Imperial College London and an intern at Oculus Research (now Meta Reality Labs). I hold a Master’s degree in Telecommunication Engineering from the University of Trento in Italy and a B.Sc. in Computer Engineering from Addis Ababa University in Ethiopia. |

|
Publications |
Last update: June, 2025 |

|
Susan Liang, Dejan Markovic, Israel D. Gebru, Steven Krenn, Todd Keebler, Jacob Sandakly, Frank Yu, Samuel Hassel, Chenliang Xu, Alexander Richard ICML, 2025 This work introduce a new framework for real-time, high-quality binaural speech synthesis using flow matching models. Rather than treating binaural rendering as a regression task, we approach it as a generative problem, allowing us to better model complex spatial cues, room reverberation, and ambient noise that aren’t present in the mono input. We design a causal U-Net architecture that predicts future audio solely based on past information, making it well-suited for streaming applications. Paper | Code | Project page |
|
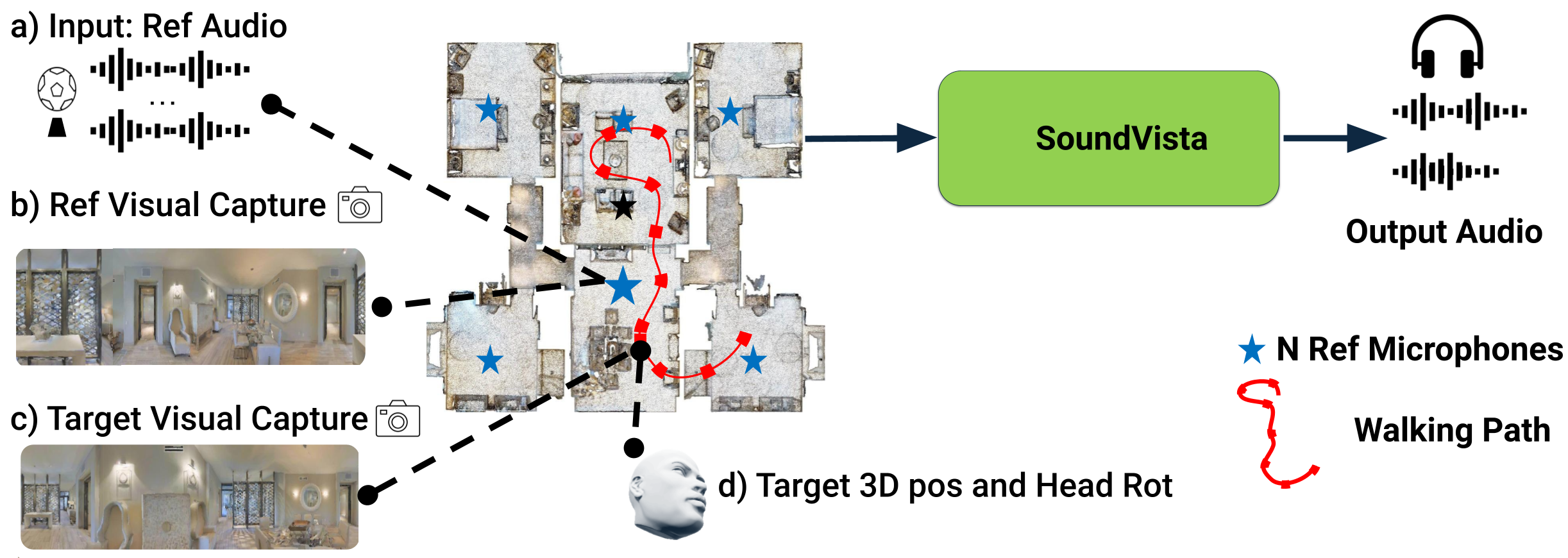
Mingfei Chen, Israel D. Gebru, Ishwarya Ananthabhotla, Christian Richardt, Dejan Markovic, Steven Krenn, Todd Keebler, Jacob Sandakly, Alexander Richard, Eli Shlizerman CVPR, 2025 (Highlight) SoundVista is a novel method for synthesizing binaural ambient sound from arbitrary viewpoints in a scene. It leverages pre-acquired audio recordings and panoramic visual data to generate spatially accurate sound without requiring detailed knowledge of individual sound sources. Paper | Code | Project page | Demo video |

|
Israel D. Gebru, Dejan Markovic, Steven Krenn, Todd Keebler, Jacob Sandakly, Alexander Richard ICASSP, 2025 We introduce a novel neural network model for rendering binaural audio directly from ambisonic recordings. Paper | Code | Dataset | Results |
|
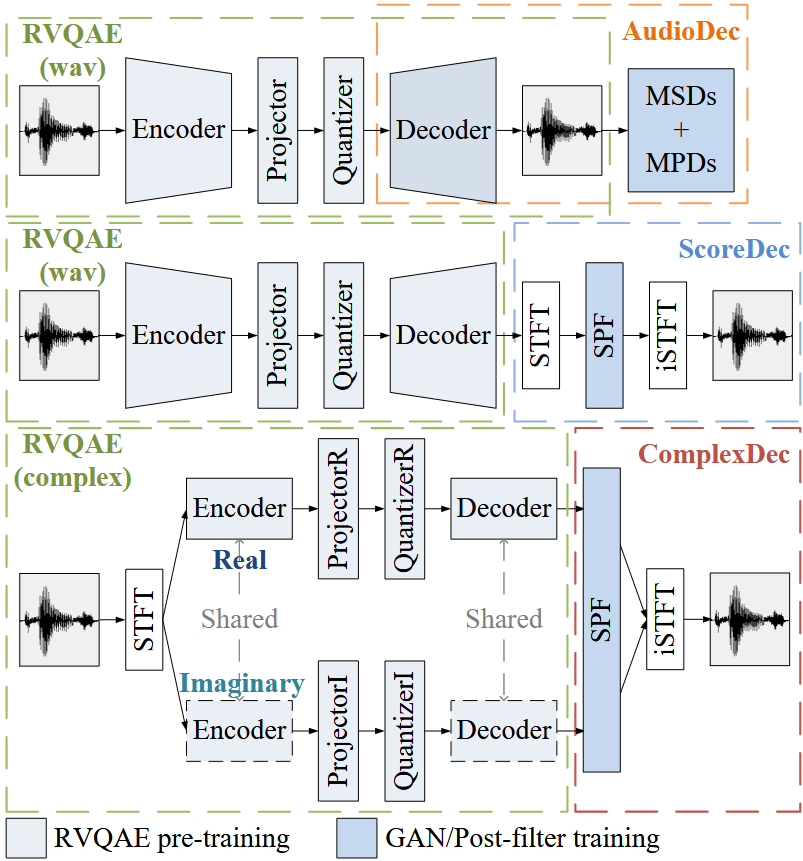
Yi-Chiao Wu, Dejan Markovic, Steven Krenn, Israel D. Gebru, Alexander Richard ICASSP, 2025 This work introduces a neural speech codec that uses complex spectral input to ease the information loss and avoid the issues with temporal and high-dimensional compression. Paper | Code |

|
Ziyang Chen, Israel D. Gebru, Christian Richardt, Anurag Kumar, William Laney, Andrew Owens, Alexander Richard CVPR, 2024 (Highlight) We present the Real Acoustic Fields (RAF) dataset that captures real acoustic room data from multiple modalities. The dataset includes high-quality and densely captured room impulse response data paired with multi-view images, and precise 6DoF pose tracking data for sound emitters and listeners in the rooms. Paper | Dataset | Project page |
|
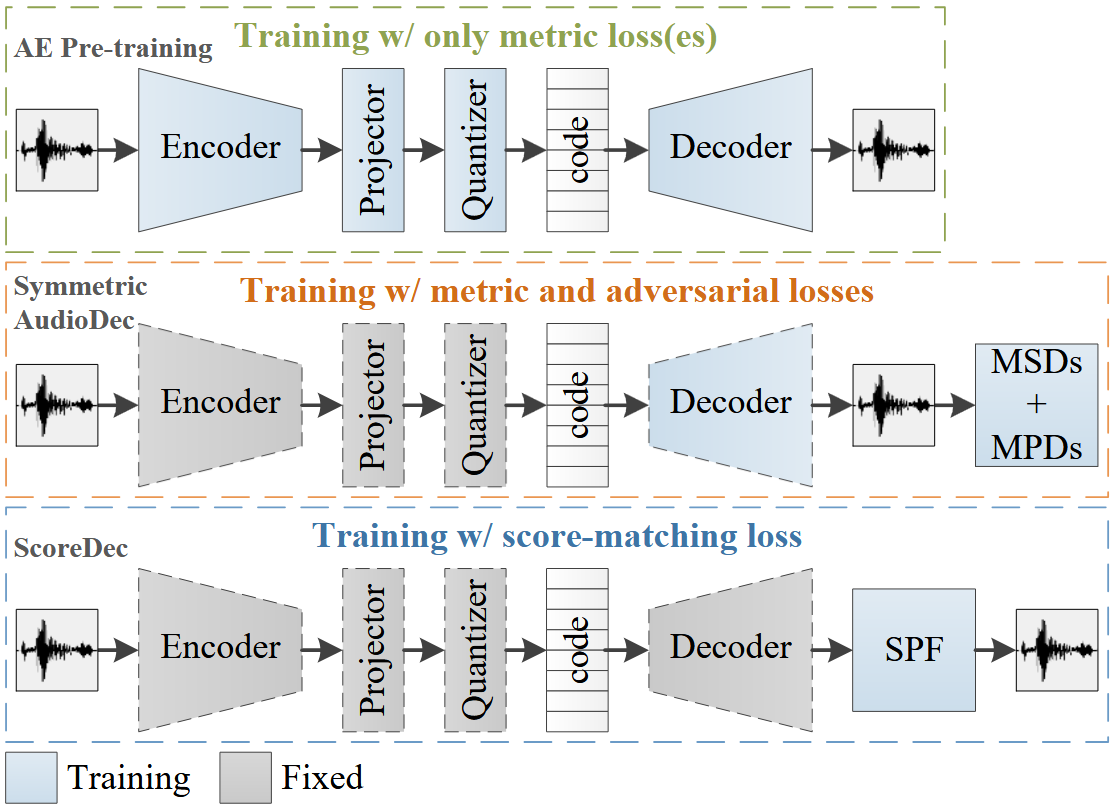
Yi-Chiao Wu, Dejan Markovic, Steven Krenn, Israel D. Gebru, Alexander Richard. ICASSP, 2024 We developed a score-based diffusion post-filter (SPF) in the complex spectral domain to eliminate the challenging and opaque GAN training used in neural codecs. As a result, we achieved impressive coded audio quality for full-band 48 kHz speech with human-level naturalness and well-preserved phase information. Paper | Project page |
|
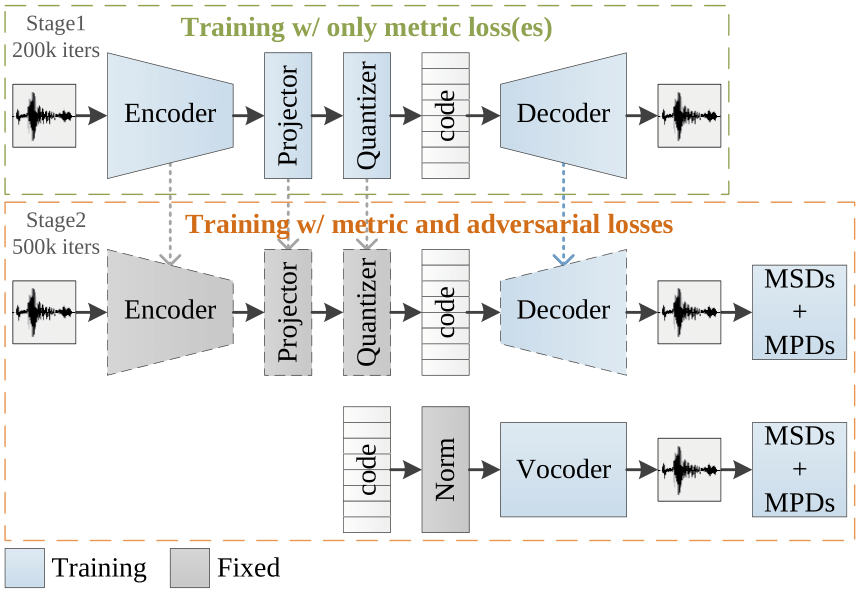
Yi-Chiao Wu, Israel D. Gebru, Dejan Marković, Alexander Richard ICASSP, 2023 We introduce a neural audio codec designed for real-time, high-quality audio compression and streaming applications. Paper | Code | Demo |
|
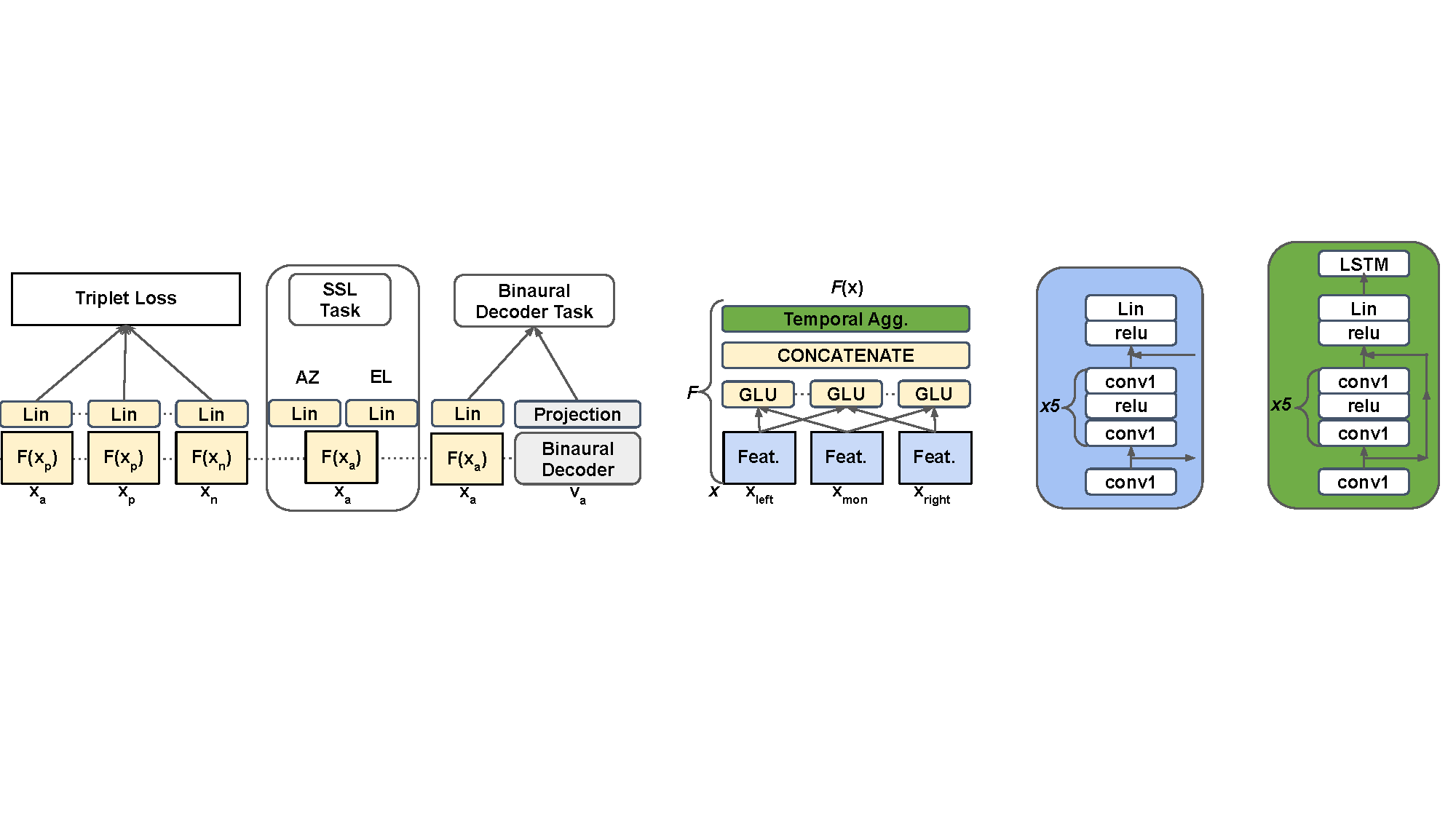
Pranay Manocha, Israel D. Gebru, Anurag Kumar, Dejan Markovic, Alexander Richard Interspeech, 2023 We introduce a novel objective metric designed to evaluate the spatialization quality (SQ) between pairs of binaural audio signals, independent of speech content and signal duration. Paper |
|
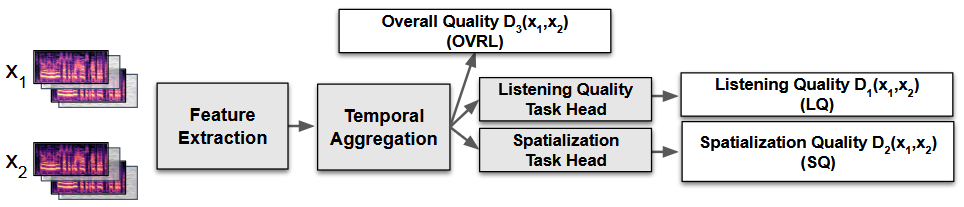
Pranay Manocha, Anurag Kumar, Buye Xu, Anjali Menon, Israel D. Gebru, Vamsi K Ithapu, Paul Calamia Interspeech, 2022 We introduce a novel metric for evaluating both listening quality (LQ) and spatialization quality (SQ) between pairs of binaural audio signals without relying on subjective data. Paper |
|
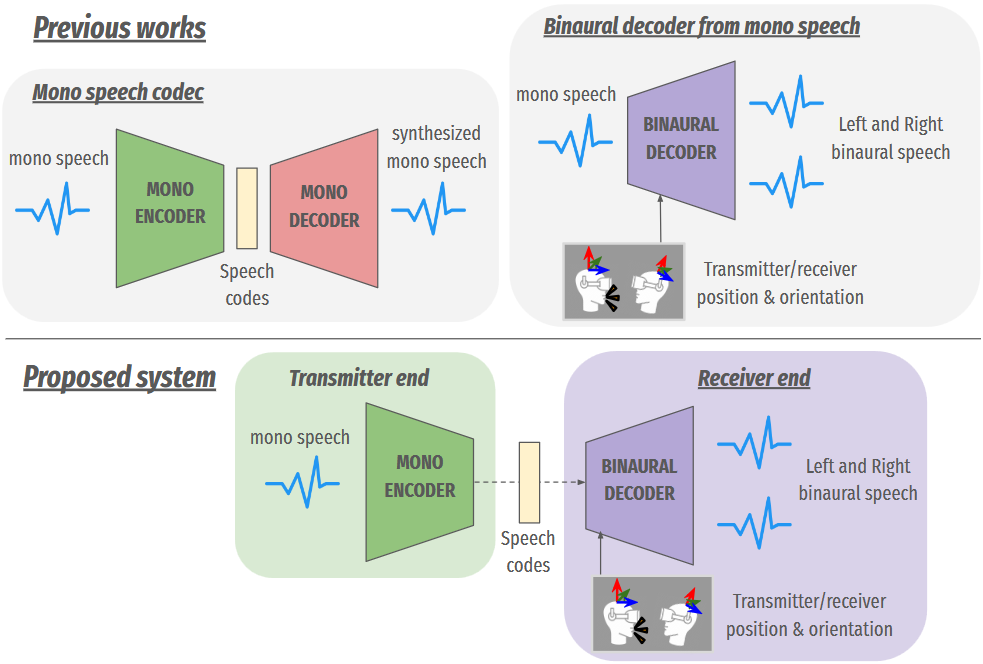
Wen Chin Huang, Dejan Markovic, Israel D. Gebru, Alexander Richard, Anjali Menon Interspeech, 2022 This work presents an End-to-end framework that integrates a low-bitrate audio codec with a binaural audio decoder to accurately synthesize spatialized speech. We used a modified vector-quantized variational autoencoder, trained with carefully designed objectives, including an adversarial loss, to improve the authenticity of the generated audio. Paper | Project page |
|
Alexander Richard, Dejan Markovic, Israel D. Gebru, Steven Krenn, Gladstone Alexander Butler, Fernando Torre, Yaser Sheikh ICLR, 2021 (won outstanding paper award) This work presents a novel neural rendering approach for real-time binaural sound synthesis. The proposed network converts single-channel audio into two-channel binaural sound, conditioned on the listener's relative position and orientation to the source. Paper | code | Project page |
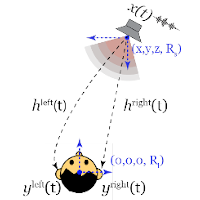
|
Israel D. Gebru, Dejan Marković, Alexander Richard, Steven Krenn, Gladstone A Butler, Fernando De la Torre, Yaser Sheikh ICASSP, 2021 This work introduces a data-driven approach to implicitly learn Head-Related Transfer Functions (HRTFs) using neural networks. Traditional HRTF measurement methods are often cumbersome, requiring listener-specific recordings at numerous spatial positions within anechoic chambers. In contrast, this study proposes capturing data in non-anechoic environments and employing a neural network to model HRTFs. Paper | dataset |
|
Pranay Manocha, Anurag Kumar, Buye Xu, Anjali Menon, Israel D. Gebru, Vamsi K Ithapu, Paul Calamia WASPAA, 2021 This work introduces a novel framework for evaluating spatial localization differences between binaural recordings. Paper | presentation |
|
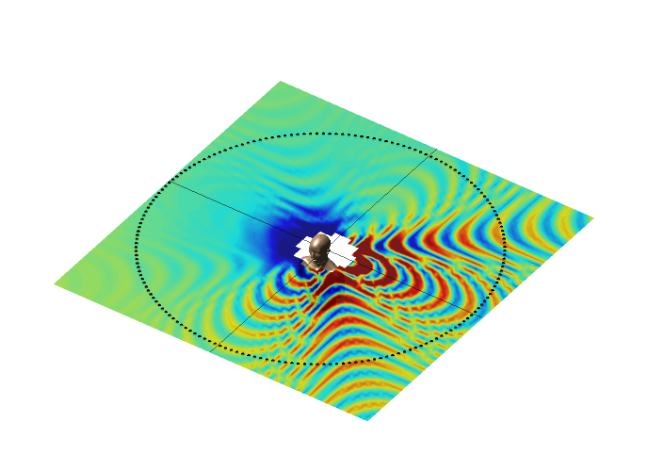
Federico Borra, Steven Krenn, Israel D. Gebru, Dejan Marković WASPAA, 2019 This paper discusses the implementation of a system for large area sound field recording and reconstruction and proposes an improved sound field reconstruction algorithm. Paper | Demo Video |
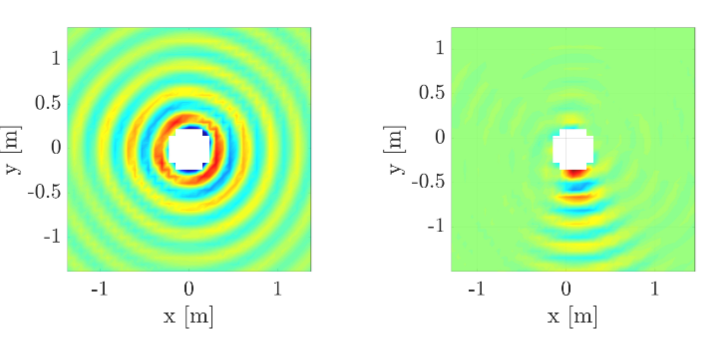
|
Federico Borra, Israel D. Gebru, Dejan Marković ICASSP, 2019 This paper addresses the problem of soundfield reconstruction over a large area using a distributed array of higher-order microphones. Paper |
|
|
Israel D. Gebru, Christine Evers, Patrick A Naylor, Radu Horaud HSCMA, 2017 (won best paper award) This paper proposes a novel audio-visual tracking approach that exploits constructively audio and visual modalities in order to estimate trajectories of multiple people in a joint state space. The tracking problem is modeled using a sequential Bayesian filtering framework Paper | presentation | Code | Demo Video |
|
|